| ARIMA模型 | 您所在的位置:网站首页 › q检验 spss › ARIMA模型 |
ARIMA模型
|
欢迎转载,转载请注明出处: https://blog.csdn.net/qq_41709378/article/details/105869122 ———————————————————————————————————————————————————— 简介: ARIMA模型:(英语:Autoregressive Integrated Moving Average model),差分整合移动平均自回归模型,又称整合移动平均自回归模型(移动也可称作滑动),是时间序列预测分析方法之一。AR是“自回归”,p为自回归项数;MA为“滑动平均”,q为滑动平均项数,d为使之成为平稳序列所做的差分次数(阶数)。 由于毕业论文要涉及到时间序列的数据(商品的销量)进行建模与分析,主要是对时间序列的数据进行预测,在对数据进行简单的散点图观察时,发现数据具有季节性,也就是说:数据波动呈现着周期性,并且前面的数据会对后面的数据产生影响,这也符合商品的销量随时间波动的影响。于是选择了ARIMA模型,那为什么不选择AR模型、MA模型、ARMA模型??? 于是,通过这篇博客,你将学到: (1)通过SPSS操作ARIMA模型 (2)运用python进行白噪声数据判断 (3)为什么差分,怎么定阶 PS:在博客结尾,会附录上Python进行ARIMA模型求解的代码。 为什么会使用SPSS? 由于真香定理,在SPSS里有ARIMA、AR、MA模型的各种操作;还包括异常值处理,差分,白噪声数据判断,以及定阶。 一种很方便又不用编程还可以避免改代码是不是很爽… ARIMA模型的步骤好啦,使用ARIMA模型的原因: 在过去的数据对今天的数据具有一定的影响,如果过去的数据没有对如今的数据有影响时,不适合运用ARIMA模型进行时间序列的预测。 使用ARIMA进行建模的步骤:
接下来,就是用SPSS与Python进行实操。 1 原始数据预处理首先数据来源是:2019年华中赛数学建模B题的数据。通过对一部分数据进行筛选后得到了可以运用模型建立的数据。如下图所示: 在获取了预处理后的数据后,我们就可以进行下一步平稳性检验;简单来说,平稳性也就是时间序列的数据是不是在某一数据上下波动,转化成数学术语就是:均值和反差不会随着时间变化而变化。于是可以使用SPSS画出数据的散点图,然后通过散点图的图像显示来判断是否是平稳性数据,如果不是平稳的数据就需要进行差分。 差分后的数据为:
获取了差分后的数据SS73210_1后,运用Python进行白噪声检验,要进行白噪声检验的目的:检验围绕某一条线上下波动的时间序列数据是不是随机上下波动的。 (白噪声数据:随机数据,Sig>0.05,则是白噪声序列,则历史的数据不能对未来进行预测和推断,及残差的ACF在置信区间内,可以认为等于0,过去的数据影响到今日的数据的这部分数据,这份信息已经被这个模型给提取出来了。) 接下来就是运用Python进行对序列的白噪声判断: ''' 1.实现一阶差分的白噪声数据的判断 ''' import pandas as pd from statsmodels.stats.diagnostic import acorr_ljungbox as lb path = 'D:/Python/Python_learning/HBUT/预处理/ARIMA.xlsx' df1 = pd.read_excel(path) p_value = lb(df1, lags= 1) print('白噪声检验p值:', p_value)检验结果: 白噪声检验p值: (array([28.53145736]), array([9.21884666e-08])结果分析:原假设为数据是白噪声的数据,由于模型检验的p值为9.21884666e-08小于0.05,为小概率事件,认为原假设成立不是白噪声数据。所以需要运用ARIMA模型进行重新定阶。 4 重新定阶ARIMA模型的定阶有两个参数p,q,一般可以通过具体的自相关,偏相关图的截尾来确定阶数,这里使用SPSS的操作进行自己定阶,然后通过显著性sig参数来判断模型定阶后的参数是够可靠。 1:这里有SPSS自动的操作:“专家建模器”
PS:编写Python,进行参数定阶 ''' #相对最优模型(p,q) data_ = data_.astype(float) #销量转为float类型 #定阶 pmax = int(len(D_data)/30) #一般阶数不超过length/10 qmax = int(len(D_data)/30) #一般阶数不超过length/10 bic_matrix = [] #bic矩阵 for p in range(pmax+1): tmp = [] for q in range(qmax+1): try: #存在部分报错,所以用try来跳过报错。 tmp.append(ARIMA(data_, (p, 1, q)).fit().bic) except: tmp.append(None) bic_matrix.append(tmp) bic_matrix = pd.DataFrame(bic_matrix) #从中可以找出最小值 p, q = bic_matrix.stack().idxmin() #先用stack展平,然后用idxmin找出最小值位置。 print(u'BIC最小的p值和q值为:%s、%s' %(p, q)) ''' 5 预测在选好了参数后,我们需要运用模型进行后来5天的销量进行预测。 这里运用Python进行预测: # 选取好p,q后进行ARIMA预测 model = ARIMA(data_, (p,1,q) ).fit() # 建立ARIMA(1, 1, 1)模型 model.summary2() # 给出一份模型报告 r = model.forecast(5) # 做出未来五天的预测结果 pro_r = r[0]预测结果: 做出未来五天的预测结果: [ 9.49325086 9.25931922 10.35808756 8.96617407 9.23941594]我这里也加上了完整的ARIMA算法的Python的代码: # -*- coding: utf-8 -*- # @Time : 2020/4/3 22:50 ''' 1.运用模型:ARIMA ''' import pandas as pd import numpy as np import matplotlib.pyplot as plt import seaborn as sns #seaborn画出的图更好看,且代码更简单,缺点是可塑性差 from statsmodels.graphics.tsaplots import plot_acf #自相关图 from statsmodels.tsa.stattools import adfuller as ADF #平稳性检测 from statsmodels.graphics.tsaplots import plot_pacf #偏自相关图 from statsmodels.stats.diagnostic import acorr_ljungbox #白噪声检验 from statsmodels.tsa.arima_model import ARIMA #引入ARIMA模型 #seaborn 是建立在matplotlib之上的 #文件的导入,和data的选取。 inputfile = 'D:/Python/Python_learning/HBUT/model_3/test_four.xlsx' data = pd.read_excel(inputfile ,sheet_name= 'Sheet2', index_col = '日期') print(data.head()) print(data[-5:]) data_1 = data['SS81346']; data_2 = data['SS81004'] data_3 = data['SS73210']; data_4 = data['SS81516']; data_5 = data['SS81376'] data_ = data_5 #seaborn设置背景 sns.set(color_codes=True) plt.rcParams['font.sans-serif'] = ['SimHei'] #用来正常显示中文标签 plt.rcParams['axes.unicode_minus'] = False #用来正常显示负号 plt.rcParams['figure.figsize'] = (8, 5) #设置输出图片大小 #自相关图 #自相关图显示自相关系数长期大于零,说明时间序列有很强的相关性 f = plt.figure(facecolor='white') ax1 = f.add_subplot(1, 1, 1) data_drop = data_.dropna() #将数据data dropna() plot_acf(data_drop, lags=31, ax=ax1) #平稳性检查 print(u'原始序列的ADF检验结果为:') print(ADF(data_)) #通过导入的ADF模块返回销量的平稳性检查 #单位根统计量对应的p的值显著大于0.05,最终判断该序列是非平稳序列 #1阶差分后的时序图 f = plt.figure(facecolor='white') ax2 = f.add_subplot(1, 1, 1) D_data = data_.diff().dropna() #1阶差分,丢弃na值 D_data.plot(ax = ax2) print(u'一阶差分序列的ADF检验结果为:') print(ADF(D_data)) #输出p值远小于0.05,所以1阶差分之后是平稳非白噪声序列 #绘制一阶差分前后的图像 f = plt.figure(facecolor='white') ax3 = f.add_subplot(2, 1, 1) plot_acf(D_data, lags=31, ax=ax3) #自相关 ax4 = f.add_subplot(2, 1, 2) plot_pacf(D_data, lags=31, ax=ax4) #偏相关 p = 1 q = 1 #选取好p,q后进行ARIMA预测 model = ARIMA(data_, (p,1,q) ).fit() #建立ARIMA(1, 1, 1)模型 model.summary2() #给出一份模型报告 r = model.forecast(5) #做出未来五天的预测结果 pro_r = r[0] print('做出未来五天的预测结果:') print(pro_r) #添加预测值到图像上 pre_data = pd.Series(pro_r, index=['2019/03/13', '2019/03/14', '2019/03/15', '2019/03/16', '2019/03/17'], name='SS81346') pre_data.index.name = '日期' #绘图 fig = plt.figure() ax = fig.add_subplot(1, 1, 1) ax.plot(data_, 'k', label='one') ax.plot(pre_data,'r', label='two') ax.set_title('商品: SS81376') ax.set_xlabel('日期') ax.set_ylabel('销量') ax.set_xticks(['2018/09/01', '2018/10/01', '2018/11/01', '2018/12/01', '2019/01/01', '2019/02/01', '2019/02/28', '2019/03/18']) plt.show()图像: 参考文献: 1:https://www.bilibili.com/video/BV1J7411d7wT?from=search&seid=16121932388884174904 2:https://blog.csdn.net/qq_41709378/article/details/105812871 3:https://baike.baidu.com/item/ARIMA模型/10611682?fr=aladdin |
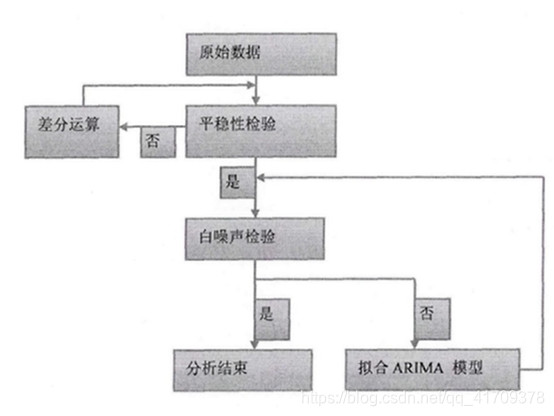 简单来说,运用ARIMA模型进行建模时,主要的步骤可以分成以下三步: (1)获取原始数据,进行数据预处理。(缺失值填补、异常值替换) (2)对预处理后的数据进行平稳性判断。如果不是平稳的数据,则要对数据进行差分运算。 (3)将平稳的数据进行白噪声检验;如果不是白噪声数据,则说明数据之间仍然有关联,需要进行ARIMA(p,d,q)重新定阶:p、q。 (4)当最后检验的数据是白噪声数据,模型结束。
简单来说,运用ARIMA模型进行建模时,主要的步骤可以分成以下三步: (1)获取原始数据,进行数据预处理。(缺失值填补、异常值替换) (2)对预处理后的数据进行平稳性判断。如果不是平稳的数据,则要对数据进行差分运算。 (3)将平稳的数据进行白噪声检验;如果不是白噪声数据,则说明数据之间仍然有关联,需要进行ARIMA(p,d,q)重新定阶:p、q。 (4)当最后检验的数据是白噪声数据,模型结束。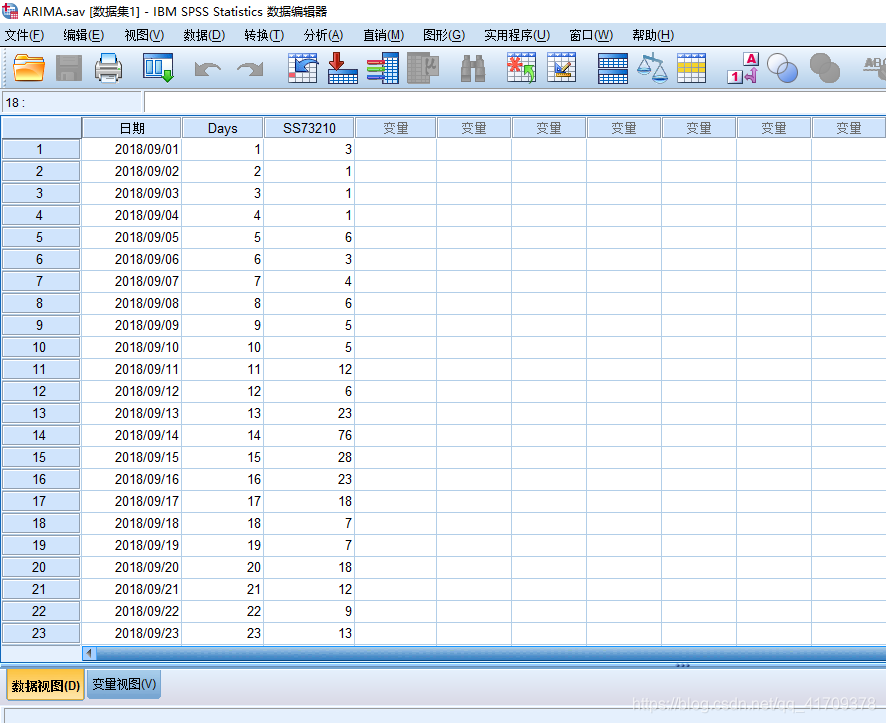 当然我们在拿到新的数据后,需要对数据进行缺失值填补,以及异常值判断。这里不再展示预处理的相关操作。下面有对应的操作链接: 缺失值填补:https://jingyan.baidu.com/article/d8072ac456536bec95cefdb6.html 异常值处理:https://wenku.baidu.com/view/bd0289ca6d85ec3a87c24028915f804d2b1687aa.html?fr=search
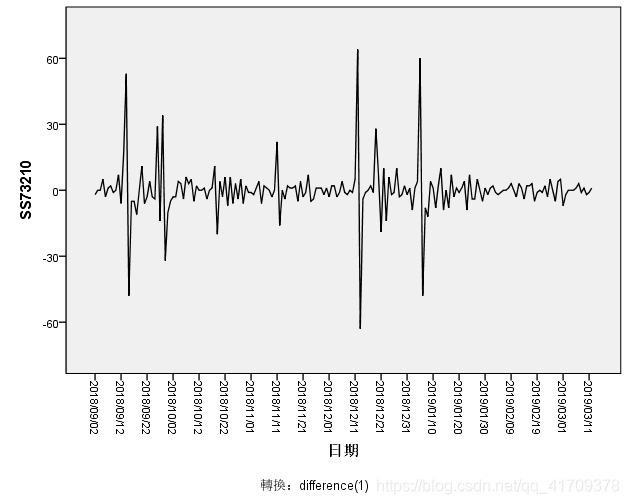
当然我们在拿到新的数据后,需要对数据进行缺失值填补,以及异常值判断。这里不再展示预处理的相关操作。下面有对应的操作链接: 缺失值填补:https://jingyan.baidu.com/article/d8072ac456536bec95cefdb6.html 异常值处理:https://wenku.baidu.com/view/bd0289ca6d85ec3a87c24028915f804d2b1687aa.html?fr=search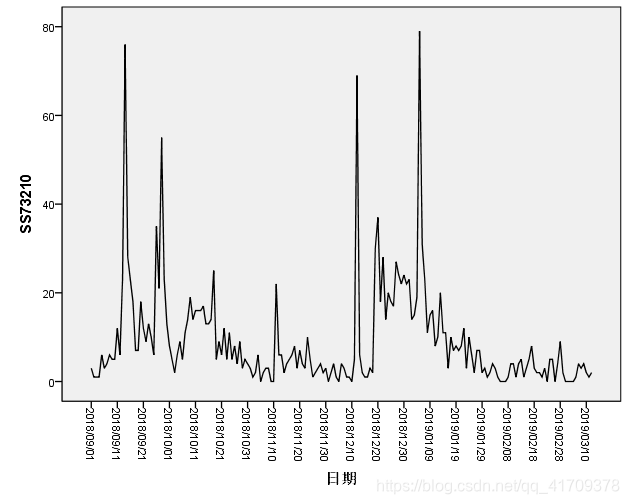 观察图像可以看出,原始数据是有很弱的季节性,但是数据是非平稳的。从2018年12月份,商品号SS73210销量就明显下降,而不是在某一确定值上下波动。于是,对数据使用一阶差分。 为什么差分? 处理非平稳的数据,消除其相关性使其变成平稳性数据。
观察图像可以看出,原始数据是有很弱的季节性,但是数据是非平稳的。从2018年12月份,商品号SS73210销量就明显下降,而不是在某一确定值上下波动。于是,对数据使用一阶差分。 为什么差分? 处理非平稳的数据,消除其相关性使其变成平稳性数据。 
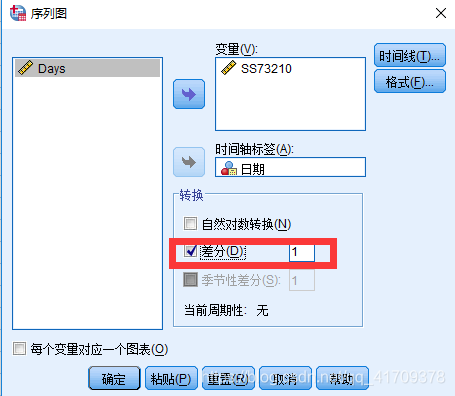
 同时,在我们获取了相应的平稳的数据后,要进行白噪声检验。 下面是获取差分后的数据值,然后与运用Python进行运算。
同时,在我们获取了相应的平稳的数据后,要进行白噪声检验。 下面是获取差分后的数据值,然后与运用Python进行运算。 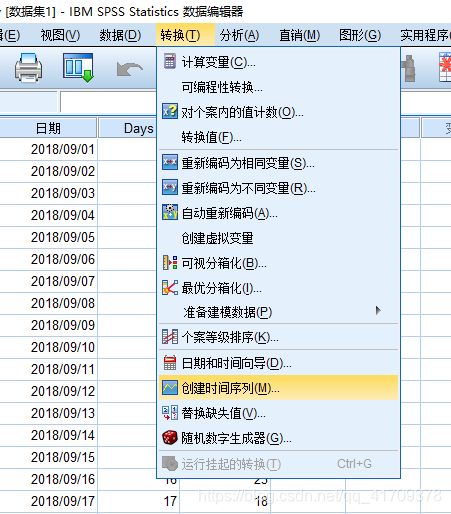
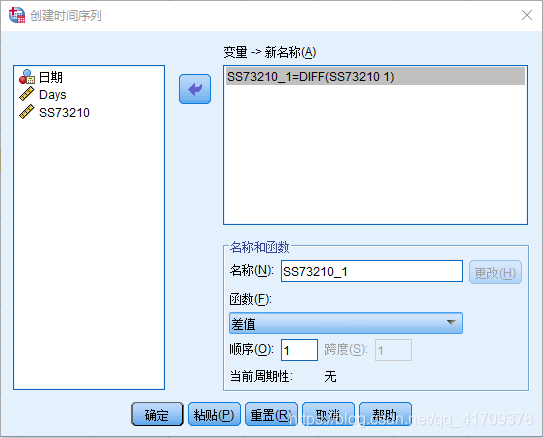
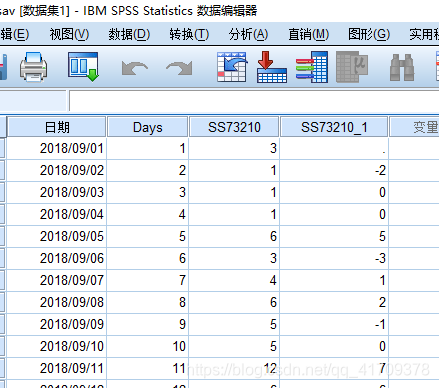 最终,获取一阶差分后的数据:SS73210_1
最终,获取一阶差分后的数据:SS73210_1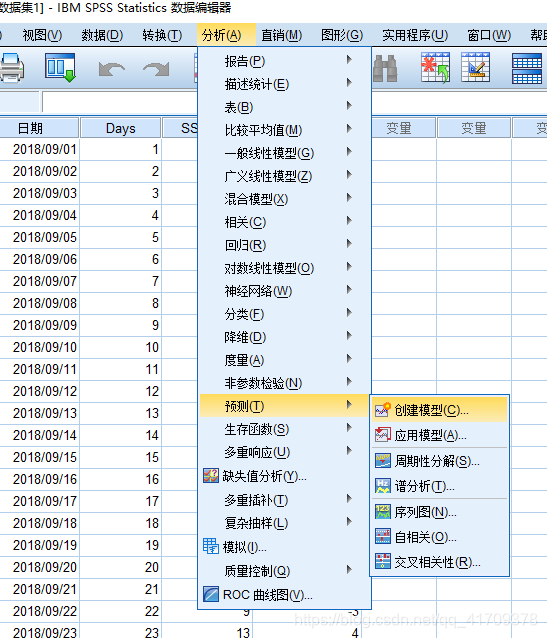
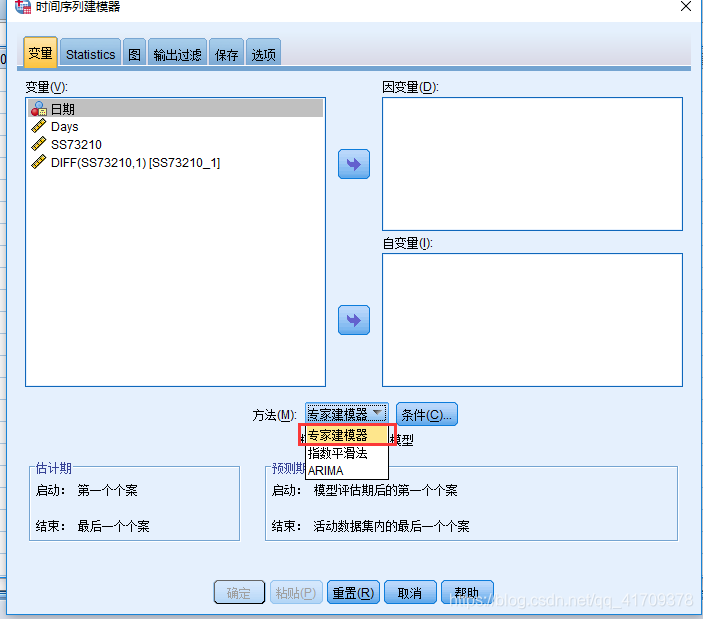 2 :也可以通过方法 “ARIMA模型” 进行自定义参数p,d,q的阶数。
2 :也可以通过方法 “ARIMA模型” 进行自定义参数p,d,q的阶数。 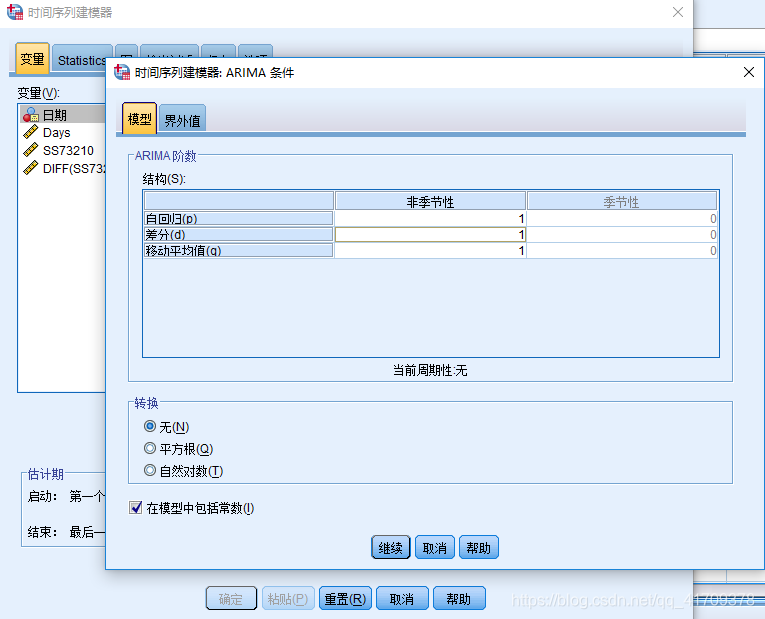 我这里选择的模型的参数p,d,q都为1,也就是进行一阶差分,p(自回归项数)与q(滑动平均项数)都为1。 下面是使用了上面的模型后的模型结果:
我这里选择的模型的参数p,d,q都为1,也就是进行一阶差分,p(自回归项数)与q(滑动平均项数)都为1。 下面是使用了上面的模型后的模型结果: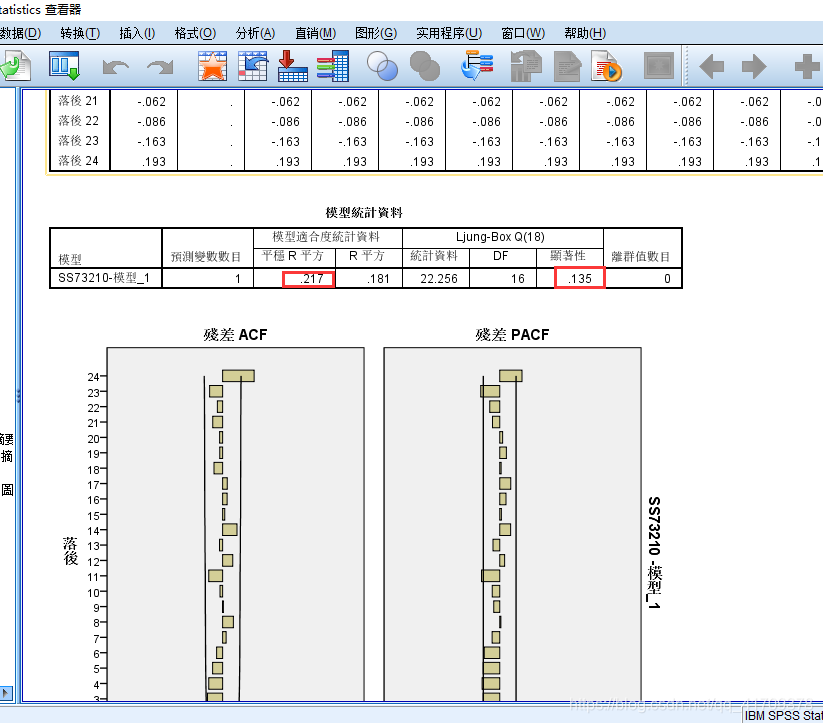
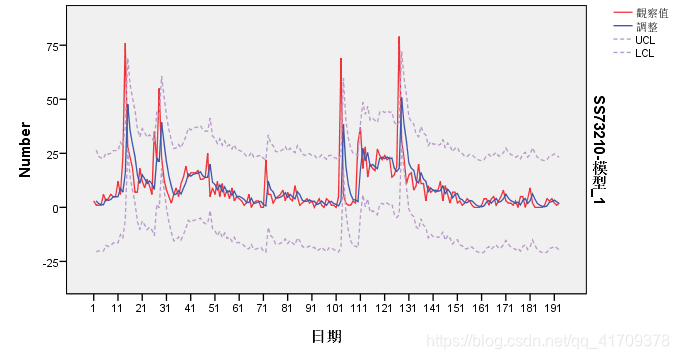 从图像可以看出运用了ARIMA模型(1,1,1)后,显著性为0.135是大于0.05,认为此模型的数据为白噪声的数据,也就是说,过去的数据影响到今日的数据的这部分数据,这份信息已经被这个模型给提取出来了。 再通过残差ACF与残差PACF也是用来看相关性,如果大部分的数据是处于两条线之间的,说明之间的数据是弱相关,几乎没有什么相关性,影响程度的信息已经被提取了。
从图像可以看出运用了ARIMA模型(1,1,1)后,显著性为0.135是大于0.05,认为此模型的数据为白噪声的数据,也就是说,过去的数据影响到今日的数据的这部分数据,这份信息已经被这个模型给提取出来了。 再通过残差ACF与残差PACF也是用来看相关性,如果大部分的数据是处于两条线之间的,说明之间的数据是弱相关,几乎没有什么相关性,影响程度的信息已经被提取了。 从图像可以看出,黑色部分的数据是原有的数据,红色的数据为销量预测的数据,可以看出预测的后5天的数据具有很好的效果,也能够很好的反映模型的预测能力。
从图像可以看出,黑色部分的数据是原有的数据,红色的数据为销量预测的数据,可以看出预测的后5天的数据具有很好的效果,也能够很好的反映模型的预测能力。【本文地址】